Webpage of Jan Claes | Methodology
Disclaimer. The information below are academic paper excerpts about some specific methodology topic. Because I believe I cannot explain it better than these authors, they are literally copied here. Please refer to the original source (mentioned at the bottom of each block), instead of incorrectly crediting me for their fantastic work.
How to develop metrics and measures?
In general, measurement is defined as the process by which numbers or symbols are assigned to attributes (e.g. complexity) of entities in the real or abstract world (e.g. business process models) in such a way as to describe them according to clearly defined rules[1]. The measurement of a process model complexity can be approached from different perspectives, depending on its theoretical foundations (e.g. software engineering, cognitive science or graph theory).
[METRIC DEFINITION] The observable value which results from the measurement is a metric,
[MEASURE DEFINITION] while a measure associates a meaning to that value by applying human judgement[2].Metrics researchers mostly agree with three-steps-procedure for defining and validating a new metric[3]: (1) metric definition, (2) metric's theoretical validation and (3) metric's empirical validation. The fourth, optional step entails the development of an IT tool for automatic metric calculation.
According to the Fenton and Pfleeger's model for software metric definition[4], the metric definition procedure includes three steps: (1) identification of the measured entity (e.g. a program's module in programming or a business process model in our case), (2) identification of desired measuring attributes of the entity (e.g. the size of a process model) and finally (3) metric definition (e.g. number of activities in a process model). After a metric is defined, we can assess its quality.
Metrics Quality characteristics
Metrics can be of different quality, depending on how precisely does a metric describes an attribute of an entity, where Latva-Koivisto[5] defined following characteristics of a good [complexity] metric:(...)
- Validity - the complexity metric measures what it is supposed to measure.
- Reliability - the measures obtained by different observers of the same process model are consistent.
- Computability - a computer program can calculate the value of the metric in a finite time and preferably quickly.
- Ease of implementation - the difficulty of implementation of the method that computes the complexity metric is within reasonable limits.
- Intuitiveness - it is easy to understand the definition of the metric and see how it relates to the instinctive notion of complexity.
- Independence of other related metrics - ideally, the value of the complexity metric is independent of other properties that are sometimes related to complexity. These include at least size and visual representation of the process.
Metrics validation
Validation of measurements and metrics is necessary to ensure that the conclusions obtained from the measurement are in fact valid and precise and that a metric actually measures the attribute it was designed to measure. The problem of defining a metric is that we have to convert abstract concepts into measurable definitions. This process can create unwanted discrepancies between the two. Validation of a measurable concept is not a trivial process, as three validation aspects or problems have to be addressed: (1) content validity, (2) criteria validity and (3) construct validity[6]. Reliability is another concept we have to address when dealing with evaluation of a measurement concept. Reliability fundamentally addresses the question of correct- ness and determinicity of a measurement concept, as well as its consistency through time and measured entities. A metric can be reliable, but not valid, where unreliable metric can never be valid[6].Theoretical validation
In literature we can mainly find three methods used for theoretical metric validation: (1) properties which result from the type of metric's measurement scale (i.e. nominal, ordinal, interval, ratio, absolute)[2], (2) metric compliance with Briand's framework properties[7] and (3) metric compliance with Weyuker's properties[8]. By considering these methods, we can find out if the metric is structurally sound and compliant with measuring theory. Some researchers (e.g. Cardoso[7], Coskun[9]) use Weyuker's properties[8] for theoretical validation of a metric. These properties were designed for the evaluation of complexity metrics for programming code, but can also be used for complexity metrics of processes and the corresponding process models. A good complexity metric should satisfy all nine properties defined by Weyuker[8]. Another way to theoretically validating a metric is through the Briand et al. framework[7], which was primarily intended for programming code metrics. According to the framework, metrics are divided into five categories, based on what they measure: size, length, complexity and cohesion or coupling, where each category contains specific properties the metric should comply with. These categories are also related to process complexity.Empirical validation
Empirical validation of a metric compliments the theoretical validation. For this purpose, researchers can use different empirical research methods, e.g. surveys, experiments and case studies. The goal of empirical validation is to find out if a metric actually measures what it was supposed to measure. Both theoretical and empirical validations of a metric are required for a metric to be structurally sound and practically useful[2].Sources:
[1] L. Finkelstein, M.S. Leaning, A review of the fundamental concepts of measurement (Jan.) Measurement 2 (1) (1984) p. 25-34.
[2] J. Cugini, et al., Methodology for evaluation of collaboration systems, Evaluation Working Gr. DARPA Intell. Collab. Vis. Progr. Rev. 3 (1997).
[3] G.M. Muketha, A.A.A. Ghani, M.H. Selamat, R. Atan, A survey of business process complexity metrics, Inf. Technol. J. 9 (7) (2010) p. 1336-1344.
[4] N.E. Fenton, S.L. Pfleeger, Software Metrics: a Rigorous and Practical Approach, PWS Publishing Co., Boston, MA, USA, (1998).
[5] A.M. Latva-Koivisto, Finding a complexity measure for business process models. (2001).
[6] J. Mendling, Metrics for Business Process Models. (Berlin, Heidelberg: Springer Berlin Heidelberg) Metr. Process Models 6 (2008), p. 103-133.
[7] L.C.Briand, C.M.Differding, and H.D.Rombach, Practical Guidelines for Measurement-Based Process Improvement, 1996.
[8] E.J. Weyuker, Evaluating software complexity measures. IEEE Trans. Softw. Eng. 14 (9) (1988) p. 1357-1365.
[9] E.Coskun, A new Complexity Measure for Business Process Models, 2014.From: G. Polancic, B. Cegnar, Complexity metrics for process models - A systematic literature review. Computer Standards & Interfaces 51 (July 2016), p. 104-117, http://doi.org/10.1016/j.csi.2016.12.003
How to evaluate methods?
The figure below summarises the Method Evaluation Model, a theoretical model for evaluating methods which incorporates both aspects of method success discussed above. The diagram shows the primary constructs and causal relationships between them.
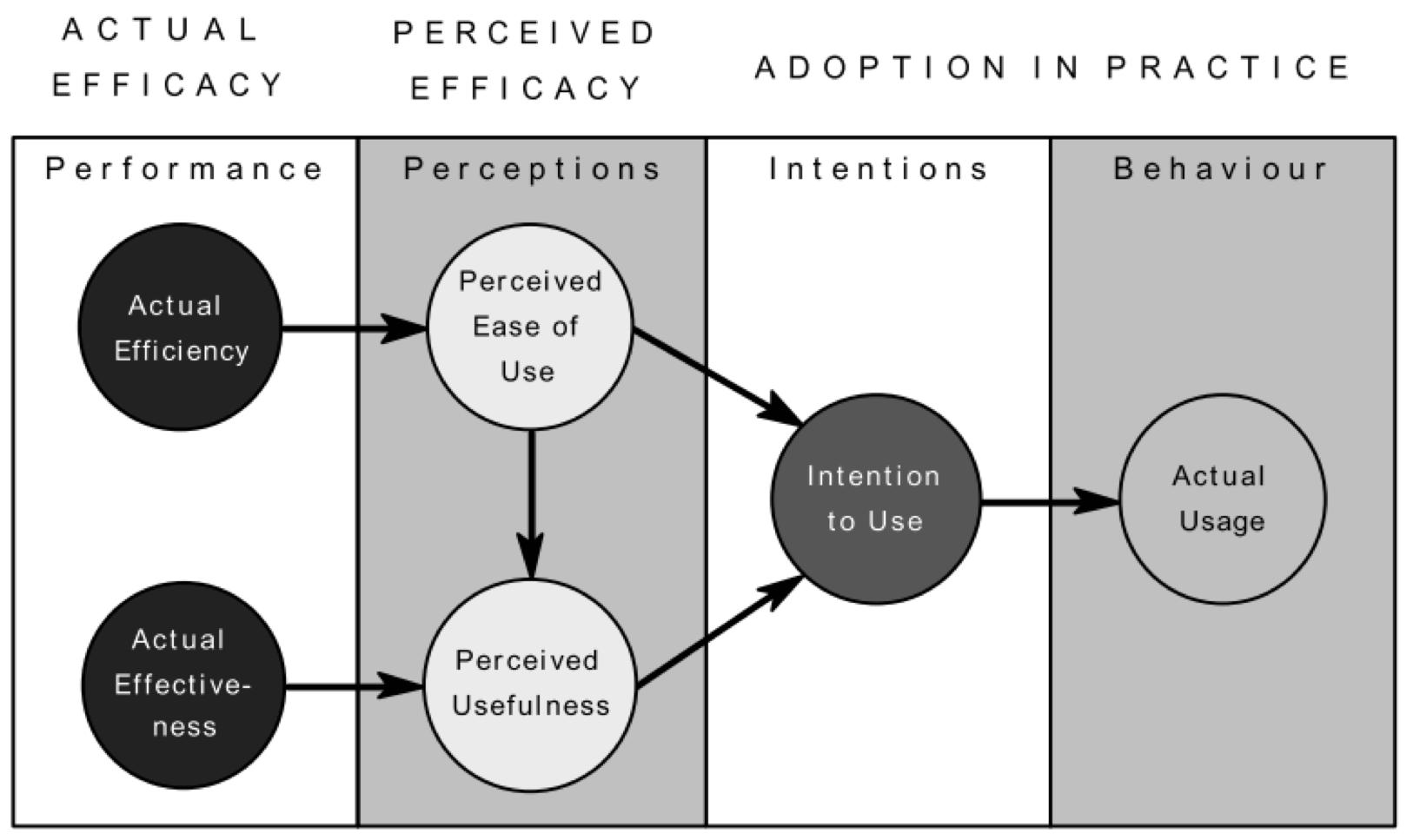
The constructs of the model are:
- Actual Efficiency: the effort required to apply a method
- Actual Effectiveness: the degree to which a method achieves its objectives
- Perceived Ease of Use: the degree to which a person believes that using a particular method would be free of effort
- Perceived Usefulness: the degree to which a person believes that a particular method will be effective in achieving its intended objectives
- Intention to Use: the extent to which a person intends to use a particular method
- Actual Usage: the extent to which a method is used in practice
Actual Efficiency and Actual Effectiveness are based on Rescher's concept of pragmatic success[1]. Efficiency of a method is defined by the effort required to apply the method. This can be measured by a variety of input measures: time, cost or effort. Effectiveness of a method is defined by how well it achieves its objectives. This can be measured by evaluating the quantity and/or quality of the results (output measures).
The three central constructs of the model are the constructs of the Technology Acceptance Model (TAM) of Davis[2]. The definitions of the constructs have been modified to reflect the change of domain from systems to methods. The definition of Perceived Usefulness is also modified to reflect the fact that the effectiveness of a method can only be evaluated in the context of its objectives[1]. The constructs of TAM are sufficiently general that they can be translated to the methods domain.
Causal Relationships (Laws of Interaction)
The following causal relationships are hypothesised between the constructs of the model:
- Perceived Ease of Use is determined by Actual Efficiency. Actual Efficiency measures the effort required to apply the method, which should determine perceptions of effort re- quired.
- Perceived Usefulness is determined by Actual Effectiveness. Actual Effectiveness measures how well the method achieves its objectives, which should determine perceptions of its effectiveness.
- Perceived Usefulness is determined by its Perceived Ease of Use. This follows from TAM. Intention to Use a method is jointly determined by its Perceived Ease of Use and Perceived Usefulness. This follows from TAM.
- Actual Usage of a method is determined by Intention to Use. This also follows from TAM.
Rescher's theory of Methodological Pragmatism predicts that methods that are more efficient and/or effective in achieving their objectives will be adopted in favour of other methods. This model proposes a slightly different view: that methods will be adopted based on perceptions of their ease of use and usefulness. Actual Efficiency and Effectiveness determine intentions to use a method only via perceptions of ease of use and usefulness. This is a subtle difference, but an important one in human behaviour, subjective reality is more important than objective reality. While perceptions of ease of use and usefulness will be partly determined by actual efficacy, they will also be influenced by other factors (e.g. prior knowledge, experience with particular methods, normative influences).
Sources:
[1] N. Recher, Methodological Pragmatism: Systems-Theoretic Approach to the Theory of Knowledge, Basil Blackwell, Oxford (1977).
[2] F.D. Davis, Perceived Usefulness, Perceived Ease of Use and User Acceptance of Information Technology, MIS Quarterly, 13 (3) (1989).
From: D.L. Moody, The method evaluation model: A theoretical model for validating information systems design methods. In: C.U. Ciborra, R. Mercurio, M. de Marco, M. Martinez, A. Carignani (eds.), Proc. 11th Eur. Conf. Inf. Syst. (ECIS '03). (AIS Electronic Library, Naples, Italy), p. 1327-1336, http://aisel.aisnet.org/ecis2003/79
Types of theories
The method for classifying theory for IS proposed here begins with the primary goals of the theory. Research begins with a problem that is to be solved or some question of interest. The theory that is developed should depend on the nature of this problem and the questions that are addressed. Whether the questions themselves are worth asking should be considered against the state of knowledge in the area at the time. The four primary goals of theory discerned are
Combinations of these goals lead to the five types of theory shown in the left-hand column [below]. The distinguishing features of each theory type are shown in the right-hand column. It should be noted that the decision to allocate a theory to one class might not be straightforward. A theory that is primarily analytic, describing a classification system, can have implications of causality. For example, a framework that classifies the important factors in information systems development can imply that these factors are causally connected with successful systems development. Some judge- ment may be needed to determine what the primary goals of a theory are and to which theory type it belongs.
- Analysis and description. The theory provides a description of the phenomena of interest, analysis of relation- ships among those constructs, the degree of generalizability in constructs and relationships and the boundaries within which relationships, and observations hold.
- Explanation. The theory provides an explanation of how, why, and when things happened, relying on varying views of causality and methods for argumentation. This explanation will usually be intended to promote greater understanding or insights by others into the phenomena of interest.
- Prediction. The theory states what will happen in the future if certain preconditions hold. The degree of certainty in the prediction is expected to be only approximate or probabilistic in IS.
- Prescription. A special case of prediction exists where the theory provides a description of the method or structure or both for the construction of an artifact (akin to a recipe). The provision of the recipe implies that the recipe, if acted upon, will cause an artifact of a certain type to come into being.
Theory Type Distinguishing Attributes I. Analysis Says what is.
The theory does not extend beyond analysis and description. No causal relationships among phenomena are specified and no predictions are made.II. Explanation Says what is, how, why, when, and where.
The theory provides explanations but does not aim to predict with any precision. There are no testable propositions.III. Prediction Says what is and what will be.
The theory provides predictions and has testable propositions but does not have well-developed justificatory causal explanations.IV. Explanation and prediction (EP) Says what is, how, why, when, where, and what will be.
Provides predictions and has both testable propositions and causal explanations.V. Design and action Says how to do something.
The theory gives explicit prescriptions (e.g., methods, techniques, principles of form and function) for constructing an artifact.From: Gregor, S. "The nature of theory in information systems", MIS Q. 30(3), 2006, pp. 611-642, http://www.jstor.org/stable/25148742
